STL is a C++ library of container classes, algorithms, and iterators; it provides many of the basic algorithms and data structures of computer science. The STL is a generic library, meaning that its components are heavily parameterized: almost every component in the STL is a template. (stl_intro)
Standard Library vs. Standard Template Library
C++ standard library includes: Input/Output, Strings, Standard Template Library (algorithm, functional, Sequence /Associative /Unordered associative containers), C standard library and misc headers. (wiki)
STL vs. OOP
Whereas OOP encapsulates data and algorithms as classes; the concept of STL is adversely based on a separation of data and operations, where data is managed by container classes, and the operations are defined by configurable algorithms, and iterators are the glue between these two components.
All components in STL are templates for any type, and hence STL serves as a good example of generic programming. As for polymorphism, whereas OOP relies on virtual funcs to achieve run-time dynamic behaviors, types in STL (or generic programming) become known during compilation.
STL is logically divided into six pieces, each consisting of generic components that interoperate with the rest of the library:
array(c++11), vector, deque, forward_list(c++11), list.set, multiset, map, multimap.unordered_set, unordered_multiset, unordered_map, unordered_multimap.All sequential containers provide fast sequential access to their elements, but differing on performance trade-offs relative to: 1) the costs to add or delete elements to the container; 2) the costs to perform nonseq access to eles in the container.
array is the only fixed-sized container
Definition needs both element type and container size.
Although we cannot copy or assign objs of built-in array types, there is no such restriction on array.
array<int, 10> ia1; //ten default-init ints
array<int, 10> ia2 = {0,1,2,3,4,5,6,7,8,9}; //list init
array<int, 10> ia3 = {42}; //ia3[0] is 42, all others are 0
array<int, 10> copy = ia2; //OK: so long as array types matcharray/string/vector hold elements in contiguous mem
array does not support element insertion or removal, vector supports fast element insertion or removal at the end, deque are designed to be efficient performing insertions/removals from either the end or the beginning (other positions are uaually less efficient than in list); list and forward_list all support fast insertion or removal of elements anywhere in the container
list and forward_list preserves validity of iterators on insertion and removal, whereas deque invalidates all of them
list and forward_list are fast to add or remove ele, but no support on random access
forward_list and array were newly added in C++11
container elements are copies
when we use an obj to init a container, or insert an obj into a container, a copy of that obj's value is placed in the container, not the obj itself.
adding elements
--> push_back
Aside from array and forward_list, every seq container (including string) supports push_back
--> push_front
list/forward_list/deque support push_front
--> insert
Inserts allows to add elements at a specified point.
It is legal to insert anywhere in a vector, deque, or string. However, doing so can be expensive.
insert copies objects into the container.
vector<string> svec;
list<string> slist;
//equivalent to calling slist.push_front("hello")
slist.insert(slist.begin(), "hello");
//no push_front on vector, but we can insert before begin()
//WARN: inserting anywhere but the end might be slow
svec.insert(svec.begin(), "hello");--> emplace
emplace_front/emplace/emplace_back construct rather than copy elements.
When we call an emplace member, we pass arguments to a constructor for the element type. The emplace members use those arguments to construct an elem directly in space managed by the container.
//iter refers to an elem in c, which holds Sales_data eles
c.emplace_back(); //uses the Sales_data default constructor
c.emplace(iter, "999-99999"); //Sales_data(string)
c.emplace_front("978-05093", 25, 15.99);
c.push_back(Sales_data("978-05093", 25, 15.99);accessing elements
c.back() returns a ref to the last ele;
c.front() returns a ref to the first ele;
c[n] returns a ref at n;
c.at(n) returns a ref at n.
c.front() = 42; //assign 42 to first ele in c
auto &v = c.back(); //get a ref to last ele
v = 1024; //changes the ele in c
auto v2 = c.back(); //v2 is NOT a ref, just a copy
v2 = 0; //no change to ele in cerasing elements
pop_front and pop_back members
these operations return void. If you need the value you are about to pop, you must store that value before doing the pop:
removing an element
erase a single ele denoted by an iterator, or a range of eles marked by a pair of iters.
return an iter referring to the loc after the (last) elem that was removed.
list<int> lst = {0,1,2,3,4};
auto it = lst.begin();
while (it != lst.end())
if(*it % 2) it = lst.erase(it)
else ++it;Lists are sequence containers that allow constant time insert and erase operations anywhere within the sequence, and iteration in both directions.
Compared to array, vector and deque, lists perform generally better in inserting, extracting and moving elements in any position within the container for which an iterator has already been obtained.
The main drawback of list and forward_list compared to other sequence containers is that they lack direct access to the elements by their pos.
list<char> coll; //list container for char eles
for(char c='a'; c<='z'; ++c)
coll.push_back(c);
//print use range-based for loop
for(auto& elem : coll)
cout << elem << endl;
//print use conventional way
while(!coll.emptu()) {
coll << coll.front() << endl; //returns 1st elem
coll.pop_front(); //removes 1st elem
}Double-ended queues are sequence containers with dynamic sizes that can be expanded or contracted on both ends. deques are not guaranteed to store all its elements in contiguous storage locations. Elems of a deque can be scattered in different chunks of storage, with the container keeping the necessary info internally to provide direct access to any of its elems in constant time and with a uniform sequential interface (through iters).
std::deque<std::string> numbers;
numbers.push_back("abc");
std::string s = "def";
numbers.push_back(std::move(s));
for(auto&& i : numbers) std::cout << std::quoted(i) << ' ';
std::cout << "\nMoved-from string holds " << std::quoted(s) << '\n';Deque is typically implemented as a bunch of individual blocks, with the first block growing in one direction and the last block growing in the opposite direction.
Pointers, references and iterater all provide indirect accesses to objects, but they are different:
Operations that add or remove elems from a container can invalidate ptrs, refs or iters to container elems. An invalidated ptr, ref, or iter is one that no longer denotes an elem.
After an oper that adds elems to a container:
vector or string are invalid if the container was reallocated. If no reallocation happens, all indirect refs to elems before the insertion remain valid; those to elems after the insertion are invalid, because of the elem movement.deque are invalid if we add elems anywhere but at the front or back. If we add at front or back, iters are invalidated, but refs and ptrs to existing elems are not.list or forward_list remain valid.When we remove elems from a container, iters, ptrs and refs to the removed elems are invalidated. After we remove an elem,
list or forward_list remain valid.deque are invalidated if the removed elems are anywhere but the front or back. If we remove elems at the back, the off-the-end iter is invalidated but other iters, refs and ptrs are unaffected; they are also unaffected if we remove from the front.vector or string remain valid for elems before the removal point. Note: the off-the-end iter is always invalidated when we remove elems.writing loop that change a container:
loops that add or remove elems of a vector, string, or deque must cater to the fact that iters, refs or ptrs might be invalidated. The program must ensure that the iter, ref, or ptr is refreshed on each trip through the loop.
//remove even-valued eles, and insert a dup of odd
vector<int> vi = {0,1,2,3,4,5,6,7,8,9};
auto iter = vi.begin();
while (iter != vi.end()){
if(*iter % 2){
iter = vi.insert(iter, *iter); //dup current elem
iter += 2; //advance past this elem and the one inserted before it
} else {
iter = vi.erase(iter); //remove even elem
//don't advance the iter, iter denotes the ele after the one we erased
}
}After the call to erase, no need to increment the iter, because the iter returned from erase denotes the next elem in the sequence. After the call to insert, we increment the iter twice. insert inserts before the given pos, and returns an iter to the inserted elem. Thus, after calling insert, iter denotes the (newly added) elem in front of the one we are processing.
An adaptor is an mechanism for making one thing act like another. A container adaptor takes an existing container type and makes it act like a different type.
Each adaptor defines two constructors: the default that creates an empty obj, and a constructor that takes a container and inits the adaptor by copying the given container.
//copies eles from deq into stack
stack<int> stk(deq);By default, both stack and queue are implemented in terms of deque, and a priority_queue is implemented on a vector. We can override the default container type by naming a sequential container as a 2nd type argument when we create the adaptor:
//empty stack implemented on top of vector
stack<string, vector<string>> str_stk;
//str_stk2 is implemented on top of vector
stack<string, vector<string>> str_stk2(svec);There are constraints on which containers can be used for a given adaptor. All of the adaptors require the ability to add and remove elems, and thus they cannot be built on array. Likewise, we cannot use forward_list, because all adaptors require operations that add, remove, or access the last elem in the container.
manges its elems in LIFO, and requires only push_back, pop_back and back operations, so we can use any of remaining types to implement stack.
std::stack<std::string> cards;
cards.push("abc");
cards.push("def");
auto size = cards.size();
std::string top_val = cards.top();
//remove
cards.pop();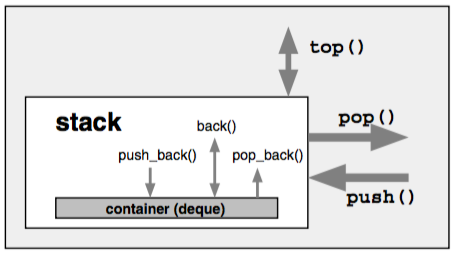
manages its elems in FIFO, and requires back, push_back, front and push_front, so it can be built on a list or deque but not a vector.
//build a stack of ints using a deque as the underlying container
std::stack<int, std::queue<int>> stk;
//build a queue of doubles using a list as the underlying container
std::queue<double, std::list<double>> que;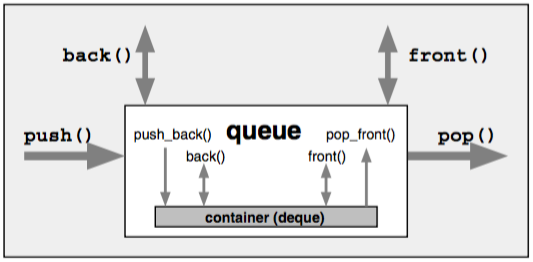
a container in which the elems may have different priorities, and the priority is based on a sorting criterion that the programmer may provide. A priority queue provides constant time lookup of the largest (by default) element, at the expense of logarithmic insertion and extraction.

requires random access in addition to front, push_back and pop_back operations, it can be built on a vector or a deque but not on a list.
templace<typename T>
void print_queue(T& q) {
while(!q.empty()){
std::cout << q.top() << " ";
q.pop();
}
std::cout << "\n";
}
int main() {
std::priority_queue<int> q;
for(int n : {1,8,5,6,3,4,0,9,7,2})
q.push(n);
print_queue(q);
std::priority_queue<int, std::vector<int>,
std::greater<int>> q2;
for(int n : {1,8,5,6,3,4,0,9,7,2})
q2.push(n);
print_queue(q2);
//using lambda to compare elements
auto cmp = [](int left, int right){
return (left^1)<(right^1);};
std::priority_queue<int, std::vector<int>,
decltype(cmp)> q3(cmp);
for(int n : {1,8,5,6,3,4,0,9,7,2})
q3.push(n);
print_queue(q3);
}
----------Output:
9 8 7 6 5 4 3 2 1 0
0 1 2 3 4 5 6 7 8 9
8 9 6 7 4 5 2 3 0 1Whereas elements in a sequential container are stored and accessed sequentially by their position, elements in an associative container are stored and retrieved by a key.
In a map, the key values are generally used to sort and uniquely identify the elems, while the mapped values store the content associated to this key. Internally, the elems in a map are always sorted by its key following a specific strict weak ordering criterion indicated by its internal comparison object.
Maps and multimaps are usually implemented as balanced trees, same with set and multisets. In fact, set, and multiset can be treated as special map and multimap, which have same value and key.
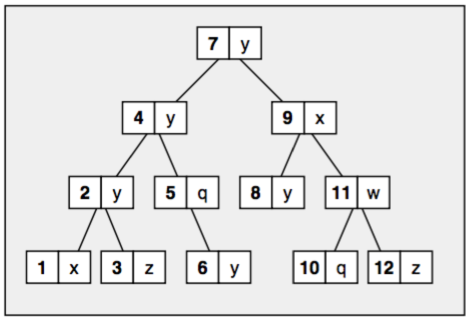
Like all standardized associative container classes, sets and multisets are usually implemented as balanced binary trees, typically red-black trees.
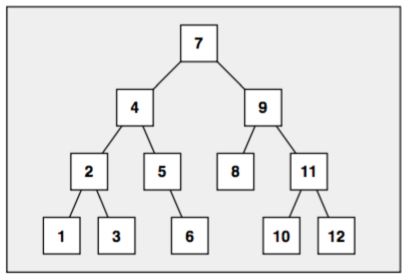
Set and multiset containers sort their elems automatically according to a certain sotring criterion. The major advantage of automatic sorting is that a binary tree performs well when elems with a certain value are searched, with logarithmic complexity. However, automatic sorting also imposes an important constraint: you may not change the value of an elem directly, because doing so might compromise the correct order. Therefore, to modify the value of an elem, you must remove the elem having the old values and insert a new elem that has the new value.
Unordered containers allow for fast retrieval of individual elems based on their keys. Internally, the elems are not sorted in any particular order w.r.t either key or mapped values, but organized into buckets depending on their hash values to allow for fast access to individual elems directly by their key values.
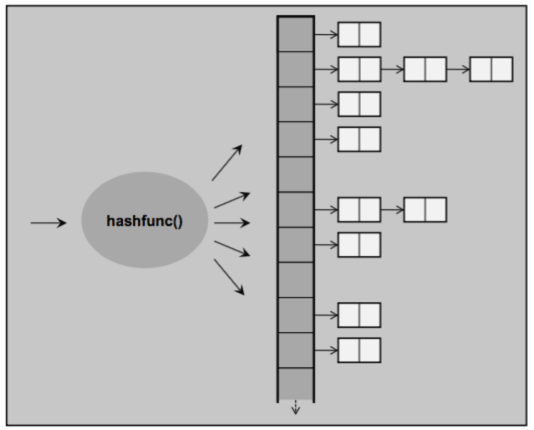
In unordered map or multimap, for each elem to store, which is a key/value pair, the hash function maps the value of the key to a bucket (slot) in the hash table. Each bucket manages a singly linked list containing all the elems for which the hash func yields the same value.
The unordered containers are organized as a collection of buckets, each of which holds zero or more elements. These containers use a hash func to map elements to buckets. To access an elem, the container first computes the elem's hash code, which tells which bucket to search. The container puts all of its elems with a given hash value into the same bucket. If the container allows multi elems with a given key, all the elems with the same key will be in the same bucket. As a result, the performance of an unordered container depends on the quality of its hash func and on the number and size of its buckets.
When a bucke holds several elems, those elems are searched sequentially to find the one we want. Typically, computing an elem's hash code and finding its bucket is a fast operation. However, if the bucket has many elems, many comparisons may be needed to find a particular elem.
By default, the unordered containers use the == operator on the key type to compare elems. They also use an obj of type hash<key_type> to generate the hash code for each elem. The library supplies versions of the hash template for the built-in types, including ptrs. It also defines hash for some of the library types, including strings and smart ptr types. Thus, we can directly define unordered containers whose key is one of the built-in types (including ptr types), or a string, or a smart ptr.
However, we cannot directly define an unordered container that uses a our own class types for its key type. We must supply our own hash template. To use Sales_data as the key, we need to supply funcs to replace both the == operator and to calculate a hash code.
size_t hasher(const Sales_data &sd){
return hash<string>()(sd.isbn());
}
bool eqOp(const Sales_data &lhs, const Sales_data &rhs){
return lhs.isbn() == rhs.isbn();
}
using SD_multiset = unordered_multiset<Sales_data,
decltype(hasher)*, decltype(eqOp)*>;
//arguments are the bucket size and ptr to the hash func and eq operator
SD_multiset bookStore(42, hasher, eqOp);A map is a collection of key-value pairs. And, map is often referred to as an associative array, which is like a "normal" array except that its subscripts don't have to be integers.
//count the number of times each word occurs in the input
map<string, size_t> word_count;
string word;
while(cin >> word)
++ word_count[word];
for(const auto &w : word_count)
cout << w.first << " occurs " <<
w.second << "times\n";A set is simply a collection of keys.
//count the number of times each word occurs in the input
map<string, size_t> word_count;
set<string> exclude = {"The", "But", "And"};
string word;
while(cin >> word)
//count only words that are not in execlude
if(exclude.find(word) == exclude.end())
++ word_count[word];defining an associative container:
map<string, size_t> word_count; //empty
//list initialization
set<string> exclude = {"the", "but", "one"};
//three elements; authors maps last name to first
map<string, string> authors = { {"Joyce", "James},
{"Xw", "Zhang"}};
vector<int> ivec{1, 1, 2, 2, 3, 3, 4, 4, 5, 5};
set<int> iset(ivec.cbegin(), ivec.cend()); //5 eles
multiset<int> miset(ivec.cbegin(), ivec.cend()); //10 elesrequirements on key type:
For the ordered containers - map, multimap, set and multiset - the key type must define a way to compare the elements. By default, the library uses < operator for the key type to compare the keys. We can customize the comparison func:
bool compareIsbn(const Sales_data &lhs, const Sales_data &rhs){
return lhs.isbn() < rhs.isbn();
}
multiset<Sales_data, decltype(compareIsbn)*> bookStore(compareIsbn);When use decltype to form a func ptr, we must add * to indicate that we're using a ptr to the given func type. We init bookstore from compareIsbn, which means that when we add elements to bookstore, those elements will be ordered by calling compareIsbn. Argument compareIsbn has the same effect as &compareIsbn, as a func name is automatically converted into a ptr when needed.
the pair type
pair is a library type defined in utility header. A pair holds two data members.
pair<string, string> anon; //holds two strs
pair<string, size_t> word_count; //holds a str and an size_t
pair<string, vector<int>> line; //holds a str and vector<int>
pair<string, string> author{"XW", "Zhang"};
pair<string, int>
process(vector<string> &v){
//process v
if(!v.empty())
return {v.back(), v.back().size()}; //list init
//also OK: return pair<string, int>(...)
//also OK: return make_pair<string, int> (...)
else
return pair<string, int>();
}map types onlyset, same as key_type; for map, pairset<string>::value_type v1; //v1 is a string
set<string>::key_type v2; //v2 is a string
map<string, int>::value_type v3; //v3 is a pair<const string, int>
map<string, int>::key_type v4; //v4 is a string
map<string, int>::mapped_type v5; //v5 is an intassociative container types
when we dereference an iterator, we get a reference to a value of the container's value_type. For map, it is a pair in which first holds the const key and second holds the value:
//get an iter to an element in word_count
auto map_it = word_count.begin();
//*map_it is a ref to a pair<const string, size_t> object
cout << map_it->first; //key
cout << map_it->second; //value
map_it->first = "new key"; //ERROR: key is const
++ map_it->second; //OK: can change value through an iterIterators for sets are const
although the set types define both the iterator and const_iterator types, both give read-only access to the elements in set:
set<int> iset = {0,1,2,3,4,5,6,7,8,9};
set<int>::iterator set_it = iset.begin();
if(set_it != iset.end()) {
*set_it = 42; //ERROR: keys in a set are read-only
cout << *set_it << endl; //OK: can read the key
}Iterating across an associative container
//get an iterator positioned on the 1st element
auto map_it = word_count.begin();
//compare the current iter to print the element key-value pairs
while (map_it != word_count.cend()) {
//deref the iter to print the element key-value pairs
cout << map_it->first << " " << map_it->second << endl;
++ map_it; //increment the iter to denote the next element
}In general, we do not use the generic algorithms with the associative containers, because:
const, cannot be passed to algorithms that write to or reorder container elements;adding elements
the insert members add one element or a range of elements. Because map and set contain unique keys, inserting an element that is already present has no effect:
vector<int> ivec = {2,4,6,8,2,4,6,8}; //ivec has 8 eles
set<int> set2; //empty set
set2.insert(ivec.cbegin(), ivec.cend()); //set2 has 4 eles
set2.insert({1,3,5,7,1,3,5,7}); //set2 now has 8 eles
//four ways to add word to word_count
word_count.insert({word, 1}); //easiest way
word_count.insert(make_pair(word, 1));
word_count.insert(pair<string, size_t>(word, 1));
//construct a new obj of the pair type to insert
word_count.insert(map<string, size_t>::value_type(word, 1));c.insert(args) vs. c.emplace(args)
insert, args are used to construct an element;emplace, return from insert
insert (or emplace) returns a pair telling whether the insertion happened. The first member of the pair is an iterator to the element with the given key; the second is bool indicating whether that element was inserted, or was already there.
map<string, size_t> word_count;
string word;
while (cin >> word) {
//if word is already in word_count, insert does nothing
auto ret = word_count.insert({word, 1});
if(!ret.second) //word was already in word_count
++ ret.first->second; //increment the counter
}++ ((ret.first)->second):
ret holds the value returned by insert, which is a pairret.first is the first member of that pair, which is a map iterator referring to the element with the given keyret.first-> dereferences that iter to fetch that element. Eles in the map are also pairsret.first->second is the value part of the map element pair++ret.first->second increments that valueerasing elements
the associative counters define three versions of erase (c.erase(k), c.erase(p), c.erase(b, e)); as with sequential containers, we can erase one element or a range of elements by passing erase an iterator or an iter pair. The additional erase operation takes a key_type argument:
//erase on a key returns #elements removed
word_count.erase(removal_word);
auto cnt = authors.erase("XW, Zhang");subscripting a map
the map and unordered_map containers provide the subscript operator and a crspding at func. set types do not support subscripting because there is no "value" associated with a key; multimap and unordered_multimap don't support subscript because there may be more than one value associated with a given key.
map subscript takes an index (i.e., a key) and fetches the associated value; however, if the key is not already present, a new element is created and inserted into the map for that key. The associated value is value initialized.
map<string, size_t> word_count; //empty map
//insert a value-inited element with key Anna; then assign 1 to its val
word_count["Anna"] = 1;the following steps take place:
word_count is searched for the element whose key is Anna. Not found.Unlike vector or string, the type returned by the map subscript operator (get mapped_type) differs from the type returned by dereferencing (get value_type) a map iter.
accessing elements
set<int> iset = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
iset.find(1); //returns an iter that refers to the ele with key==1
iset.find(11); //returns the iter == iset.end()
iset.count(1); //returns 1
iset.count(11); //returns 0
if(word_count.find("foobar") == word_count.end())
cout << "foobar is not in the map" << endl;for multimap and multiset, there may be multi elements with the given key, those eles will be adjacent within the container.
string search_item("Alain de Botton"); //author we'll look for
auto entries = authros.count(search_item); //number of eles
auto iter = authors.find(search_item); //first entry for this author
//loop through the #entries there are for this author
while(entries) {
cout << iter->second << endl; //print each title
++ iter; //advance to the next title
-- entries; //keep track of how many we've printed
}alternatively, we can solve the problem using lower_bound and upper_bound, each takes a key and returns an iterator.
If the key is in the container, the iter returned from lower_bound will refer to the 1st instance of that key and an iter returned by upper_bound will refer just after the last instance of the key. If the ele is not in the multimap, then lower_bound and upper_bound will return equal iters; both will refer to the point at which the key can be inserted without disrupting the order. Thus, calling lower_bound and upper_bound on the same key yields an iter range that denotes all the eles with that key.
//beg and end denote the range of eles for this author
for(auto beg = authors.lower_bound(search_item),
end = authors.upper_bound(search_item);
beg != end; ++beg)
cout << beg->second << endl; //print each titlethird way:
//pos holds iters that denote the range of eles for this key
for(auto pos = authors.equal_range(search_item);
pos.first != pos.second; ++pos.first)
cout << pos.first->second << endl; //print each titleAll containers define their own iterator types, so we don't need a special header file for using iters of containers. However, several definitions for special iters, such as reverse iters, and some auxiliary iter funcs are introduced by the
Iters are objects that can iterate over elems of a sequence via a common interface that is adapted from ordinary ptrs. Iterators follow the concept of pure abstraction: anything that behaves like an iter is an iter.
Iterators are subdivided into categories based on their general abilities:
forward_list is forward iters, and the iters of unordered are "at least" forward iters.list, set, multiset, map and multimap are birectional iters.vector, deque, array and string are random access iters.iterators are pure abstractions. Anything that behaves like an iter is an iter. STL provides several predefined special iters: iterator adapters.
insert iterators (inserters): are used to let algs operate in insert mode rather than in overwrite mode. Three different insert iters are defined w.r.t where the elems are inserted - at the front, at the end, or at a given position.
list<int> coll1 = {1, 2, 3, 4, 5, 6, 7, 8, 9};
//copy the elems of coll1 into coll2 by appending them
vector<int> coll2;
copy(coll1.cbegin(), coll1.cend(), //source
//back_inserter(container) --> push_back(val)
// defined in vector, deque, list and string
back_inserter(coll2)); //dest
deque<int> coll3;
copy(coll1.cbegin(), coll1.cend(), //source
//front_inserter(container) --> push_front(val)
// defined in deque, list and forward_list
front_inserter(coll3)); //dest
set<int> coll4;
copy(coll1.cbegin(), coll1.cend(), //source
//inserter(container, pos) --> insert(pos, val)
// defined in all containers, exept array and forward_list
inserter(coll4, coll4.begin())); //dest
stream iterators: read from or write to a stream.
Example: read all words from the standard input and print a sorted list of them.
vector<string> coll;
//read all words from the standard input
//-source: all strings until eof (or error)
//-dest: coll(inserting)
copy(istream_iterator<string>(cin), //start of source
istream_iterator<string>(), //end of source
back_inserter(coll)); //dest
//sort elems
sort(coll.begin(), coll.end());
//print all elems without duplicates
//-source: coll
//-dest: standard output (with newline bt elems)
unique_copy(coll.cbegin(), coll.cend(), //source
ostream_iterator<string>(cout, "\n")); //destreverse iterators: let algs operate backward by switching the call of an increment operator internally into a call of the decrement operator, and vice versa.
vector<int> coll;
for(int i=1; i<=9; ++i)
coll.push_back(i);
//print all elems in reverse order
copy(coll.crbegin(), coll.crend(), //source
ostream_iterator<int>(cout, " ")); //destmove iterators: convert any access to the underlying elem into a move operation.
std::list<std::string> s;
...
//copy strings into v1
std::vector<string> v1(s.begin(), s.end());
//move strings into v2
std::vector<string> v2(make_move_iterator(s.begin()),
make_move_iterator(s.end()));STL provides some auxiliary funcs for dealing with iters: advance(), next(), prev(), distance(), and iter_swap(); the first four give all iters some abilities usually provided only for random-access iters: to step more than one elem forward (or backward) and process the diff between iters. The last func allows to swap the value of two iters.
advance()
increments the position of an iter passed as the argument.
list<int> coll;
for(int i=0; i<=9; ++i)
coll.push_back(i);
list<int>::iterator pos = coll.begin();
//print actual elem
cout << *pos << endl;
//step three elems forward
advance (pos, 3); //advance() has no return
cout << *pos << endl;
//step one elem backward
advance(pos, -1);
cout << *pos << endl;
----output
1
4
3next() and prev()
auto pos = coll.begin();
while(pos != coll.end() && std::next(pos) != coll.end()) {
...
++pos;
}distance()
return the differ between two iters.
iter_swap()
swap the values to which two iters refer.
//orig:
//- 1 2 3 4 5 6 7 8 9
//swap first and second value
//- 2 1 3 4 5 6 7 8 9
iter_swap(coll.begin(), next(coll.begin()));
//swap first and last value
//- 9 1 3 4 5 6 7 8 2
iter_swap(coll.begin(), prev(coll.end()));Classes that overload the call operator allow objs of its type to be used as if they were a func. And, such classes can also store state, so they are more flexible than ordinary funcs. Objects of classes that define the call operator are referred to as function objects, which "act like funcs".
class PrintString {
public:
PrintString(ostream &o = cout, char c = ' '):
os(o), sep(c) { }
void operator()(const string &s) const { os << s << sep; }
private:
ostream &os; //stream on which to write
char sep; //char to print after each output
};
PrintString printer; //uses the defaults; prints to cout
printer(s); //prints s followed by a space on cout
PrintString errors(cerr, '\n');
errors(s); //prints s followed by a newline on cerrFunc objs are most often used as arguments to the generic algs.
for_each(vs.begin(), vs.end(), PrintString(cerr, '\n'));function objects as sorting criteria
class Person {
public:
string firstname() const;
string lastname() const;
...
};
//class for func predicate
//- operator() returns whether a person is < another
class PersonSortCriterion {
public:
bool operator() (const Person& p1, const Person& p2) const {
return p1.lastname()<p2.lastname() ||
(p1.lastname()==p2.lastname() &&
p1.firstname()<p2.firstname());
}
};
int main(){
//create a set with special sorting criterion
set<Person, PersonSortCriterion> coll;
...
}library-defined function objects
The standard library defines a set of classes that represent the arithmetic, relational, and logical operators.
Arithmetic Relational logical
plus equal_to logical_and
minus not_equal_to logical_or
multiplies greater logical_not
divides greater_equal
modulus less
negate less_equalEach class define a call operator that applies the named operation. E.g., the plus class has a func-call operator that applies + to a pair of operands.
plus<int> intAdd; //func obj that can add two int values
negate<int> intNegate; //func obj that can negate an int value
//uses intAdd::operator(int, int) to add 10 and 20
int sum = intAdd(10, 20); //i.e., sum = 30
sum = intNegate(intAdd(10, 20)); //sum=-30library func obj can be used with algs:
//passes a temp func obj that applies the <operator to two strings
sort(svec.begin(), svec.end(), greater<string>());
vector<string *> nameTable; //vector of pointers
//ERROR: the ptrs in nameTable are unrelated, so < is undefined
sort(nameTable.begin(), nameTable.end(),
[](string *a, string *b) { return a < b; });
//OK: library guarantees that less on ptr types is well defined
sort(nameTable.begin(), nameTable.end(), less<string*>());A predicate is an expr that can be called and that returns a value that can be used as a condition. The predicates used by library algs are either unary or binary ones. The algs that take predicates call the given predicate on the elems in the input range. As a result, it must be psbl to convert the elem type to the para type of the predicate.
//comparison func to sort by word len
bool isShorter(const string &s1, const string &s2){
return s1.size() < s2.size();
}
//sort on word length, shortest to longest
sort(words.begin(), words.end(), isShorter);When we sort words by size, we also want to maitain alphabetic order among the elems that have the same length, which can be achieved using stable_sort. A stable_sort alg maintains the original order among equal elems.
void elimDups(vector<string> & words){
//sort words alphabetically so we can find dups
sort(words.begin(), words.end(),);
//unique reorders the input range so that each word appears once in the
// front portion of the range and returns an iter one past the unique rang
auto end_unique = unique(words.begin(), words.end());
//erase uses a vector operation to remove nonunique elems
words.erase(end_unique, words.end());
}
elimDups(words); //put words in alpha order and remove dups
//resort by length, maintaining alpha rder among words of the same len
stable_sort(words.begin(), words.end(), isShorter);The predicates can accept only one or two parameters. Differently, we can pass any kind of callable object to an algorithm. An obj or expr is callable if we can apply the call operator to it. callables can be: funcs, func pointers, class that overload the func-call operator, and lambda expressions.
The lambda expr represents a callable unit of code. It can be thought of as an unamed, inline func. Like any func, a lambda has a return type, a para list, and a func body. Unlike a func, lambdas may be defined inside a func.
[capture list](parameter list) --> return type { function body }-> return type) to specify a return type;auto f = []{ return 42; }
cout << f() << endl;
//sort words by size, but maintain apha order of words of same size
stable_sort(words.begin(), words.end(),
[](const string &a, const string &b)
{ return a.size()<b.size(); });Although a lambda may appear inside a func, it can use vars local to that func only if it specifies which vars it intends to use. A lambda specifies the vars it will use by including those local vars in its capture list.
void biggies(vector<string> &words, vector<string>::size_type sz){
elimDups(words);
stable_sort(words.begin(), words.end(), isShorter);
//get an iter to the 1st elem whose size()>=sz
auto wc = find_if(words.begin(), words.end(),
[sz](const string &a)
{ return a.size() >= sz; });
//compute the #elems with size>=sz
auto count = words.end() - wc;
//print words of the given size or longer, each one followed by a space
for_each(wc, words.end(),
[](const string &s){ cout << s << " "; }
}lambdas are function objects
When we write a lambda, the compiler translates that expr into an unnamed obj of an unnamed class. The classes generated from a lambda contain an overloaded func-call operator.
stable_sort(words.begin(), words.end(),
[](const string &a, const string &b)
{ return a.size() < b.size(); });
//acts like an unnamed obj of a class looks like:
class ShorterString {
public:
bool operator()(const string &s1, const string &s2) const
{ return s1.size() < s2.size(); }
};By default, lambdas may not change their captured variables, and hence, the func-call operator in a class generated from a lambda is a const member func; if the lambda is declared as mutable, then the call operator is not const.
classes representing lambdas with captures
when a lambda captures a var by ref, it is up to the program to ensure that the var to which the ref refers exists when the lambda is executed. Therefore, the compiler is permitted to use hte ref directly without storing that ref as a data member in the generated class.
In contrast, classes generated from lambdas that catpure vars by value have data members crspding to each such var. These classes also have a cstr to init these data members from the value of the captured vars.
auto wc = find_if(words.begin(), words.end(),
[sz](const string &a) {
return a.size() >= sz;
}
//generate a class like:
class SizeComp {
//the synthesized class does not have a default cstr
SizeComp(size_t n) : sz(n) { } //paras for each captured var
//call operator with the same return type, paras, and body as lambda
bool operator()(const string &s) const
{ return a.size() >= sz; }
private:
size_t sz; //a data member for each var captured by val
};lambda captures and returns
when we pass a lambda to a func, we are defining both a new type and an obj of that type: the argument is an unnamed obj of this compiler-generated class type. By default, the class generated from a lambda contains a data member crspding to
the vars captured by the lambda. Like the data members of any class, the data members of a lambda are inited when a lambda obj is created.
[] empty capture list
[names] names is a comma-separated list of names local to the enclosing func;
[&] implicit by reference capture list;
[=] implicit by value capture list;
[&, id_list] id_list is a comma-separated list of zero or more vars from the enclosing function;
[=,ref_list] vars included in the ref_list are captured by ref.capture by value:
void fcn1(){
size_t v1 = 42; //local var
//copies v1 into the callable obj named f
auto f = [v1] { return v1; };
v1 = 0;
auto j = f(); //j is 42; f stores a copy of v1 when we created it
}capture by reference:
void fcn2(){
size_t v1 = 42; //local var
//the obj f2 contains a ref to v1
auto f2 = [&v1] { return v1; };
v1 = 0;
auto j = f2(); //j is 0; f2 stores v1; it doesn't store it
}implicit captures:
rather than explicitly listing the vars we want to use from the enclosing func, we can let the compiler infer which vars we use from the code in the lambda's body. & tells the compiler to capture by ref, and = says the values are captured by value.
//sz implicitly captures by value
wc = find_if(words.begin(), words.end(),
[=](const string &s)
{ return s.size() >= sz; });
//mix implicit and explicit captures
void biggies(vector<string> &words,
vector<string>::size_type sz,
ostream &os=cout, char c=' ') {
//os implicitly captured by ref, c explicitly captured by value
for_each(words.begin(), words.end(),
[&, c](const string &s) { os << s << c; });
//os explicitly captured by ref, c implicitly captured by value
for_each(words.begin(), words.end(),
[=, &os](const string &s) { os << s << c; });
}By default, a lambda may not change the value of a var that it copies by value. To change the value of a captured var, we must follow the para list with the keyword mutable.
void fcn3(){
size_t v1 = 42; //local var
//f can change the value of the var it captures
auto f = [v1]() mutable { return ++v1; };
v1 = 0;
auto j = f(); //j is 43
}whether a var captured by ref can be changed depends only on whether that ref refers to a const or nonconst type:
void fcn4(){
size_t v1 = 42; //local var
//v1 is a ref to a nonconst var
//we can change the var through the ref inside f2
auto f2 = [&v1] { return ++v1; };
v1 = 0;
auto j = f2(); //j is 1
}specifying the lambda return type
By default, if a lambda body contains any statments other than a return, that lambda is assumed to return void. Like other funcs that return void, lambdas inferred to return void may not return a value.
//a single return
transform(vi.begin(), vi.end(), vi.begin(),
[](int i) { return i<0 ? -i : i; });
//ERROR: cannot deduce the return type for the lambda
transform(vi.begin(), vi.end(), vi.begin(),
[](int i) { if(i<0) return -i; else return i; });
//OK: define a return type, trailing
transform(vi.begin(), vi.end(), vi.begin(),
[](int i) -> int
{ if(i<0) return -i; else return i; });C++ has several kinds of objects: functions and pointers to funcs, lambdas, objects created by bind, and classes that overload the func-call operator. Like any other obj, a callable obj has a type, e.g., each lambda has its own unique (unnamed) class type. Func and func-ptr types vary by their return type and argument types, etc.
However, two callable objs with different types may share the same call signature, which specifies the type returned by a call to the obj and the argument type(s) that must be passed in the call, e.g. int(int, int).
We might want to define a function table to store "pointers" to these callables. When the program nees to execute a particular operation, it will look in the table to find which func to call:
//ordinary func
int add(int i, int j) { return i+j; }
//lambda, which generates an unnamed func-obj class
auto mod = [](int i, int j) { return i%j; };
//func-obj class
struct divide {
int operator()(int denominator, int divisor) {
return denominator / divisor;
}
};
//maps an operator to a ptr to a func taking two ints and returning an int
map<string, int(*)(int, int)> binops;
//OK: add is a ptr to func of the appropriate type
binops.insert({"+", add}); //{"+", add} is a pair
//ERROR: mod is not a ptr to func
binops.insert({"%", mod});The problem is that mod is a lambda, and each lambda has its own class type, which does not match the type of the values stored in binops.
Solution is to use the new library type function.
function<int(int, int)> f1 = add; //func ptr
function<int(int, int)> f2 = divide(); //obj of a func-obj class
function<int(int, int)> f3 = [](int i, int j) //lambda
{ return i*j; };
cout << f1(4, 2) << endl; //prints 6
cout << f2(4, 2) << endl; //prints 2
cout << f3(4, 2) << endl; //prints 8we can now redefine the map using the function type, which can denote func ptrs, lambdas, or func objs, etc:
map<string, function<int(int, int)>> binops = {
{"+", add}, //func ptr
{"-", std::minus<int>()}, //lib func obj
{"/", divide()}, //user-defined func obj
{"*", [](int i, int j){ return i*j; }, //unamed lambda
{"%", mod}, //named lambda obj
};
binops["+"](10, 5); //calls add(10, 5)we cannot (directly) store the name of an overloaded func in an obj of type function; instead we can use func ptr or lambda to disambiguate:
int add(int i, int j) { return i+j; }
Sales_data add(const Sales_data&, const Sales_data&);
map<string, function<int(int, int)>>binops;
binops.insert( {"+", add} ); //ERROR: which add?
//SOL1: store a func ptr instead of func name
int (*fp) (int, int) = add; //ptr to the add ver taking two ints
binops.insert( {"+", fp} ); //OK: fp points to the right add ver
//SOL2: use lambda
//OK: use a lambda to disambiguate which ver of add we want to use
binops.insert( {"+", [](int a, int b) { return add(a, b); } });To use the same operation in many places, we should usually define a func rather than writing the same lambda expr multi times. However, it is not so easy to write a func to replace a lambda that captures local vars.
//we cannot use the func as an argument to find_if, which takes a unary predicate
bool check_size(const string &s, string::size_type sz){
return s.size() >= sz;
}we can solve the problem using bind, which takes a callable obj and generates a new callable that "adapts" the para list of the orig obj.
//FORM: auto newCallable = bind(callable, arg_list);
//check6 is a callable obj that takes one argu of type string
//and calls check_size on its given string and the value 6
auto check6 = bind(check_size, _1, 6);The call to bind has only one placeholder, which means that check6 takes a single argument. The placeholder appears first in arg_list, which means that the para in check6 crspds to the first para of check_size.
we can use bind to bind or rearrange the parameters in the given callable.
//g is callable obj that takes two arguments
auto g = bind(f, a, b, _2, c, _1);generates a new callable that takes two arguments, represented by the placeholders _2 and _1. The 1st, 2nd and 4th arguments to f are bound to the given values a, b and c, respectively.
The arguments to g are bound positionally to the placeholders, i.e, the first to _1 and the second to _2.
g(_1, _2) --> f(a, b, _2, c, _1)
//sort on word length, shortest to longest
sort(words.begin(), words.end(), isShorter);
//sort on word length, longest to shortest
sort(words.begin(), words.end(), bind(isShorter, _2, _1));By default, the arguments to bind that are not placeholders are copied into the callable obj that bind returns. However, as with lambdas, sometimes we have arguments that we want to bind but we want to pass by ref or we might want to bind an argument that has a type that we cannot copy.
//os is a local var referring to an output stream
c is a local var of type char
for_each(words.begin(), words.end(),
[&os, c](const string &s) { os << s << c; });
//we can easily write a func to do the same job
ostream &print(ostream &os, const string &s, char c){
return os << s << c;
}
//however, we can't use bind directly to replace the capture of os
// because ostream cannot be copies
for_each(words.begin(), words.end(), bind(print, os, _1, ' '));
//use library ref to pass an obj to bind without copying
for_each(words.begin(), words.end(),
bind(print, ref(os), _1, ' '));The ref func returns an obj that contains the given ref and that is itself copyable.
several algs modify dest ranges. In particular, those algs may remove elems.
The remove() alg removes elems from a range. However, using this alg for all elems of a container operates in a surprising way.
list<int> coll;
//insert elems from 6 to 1 and 1 to 6
for(int i=1; i<=6; ++i) {
coll.push_front(i);
coll.push_back(i);
}
//print all elems of the collection
cout << "pre: ";
copy(coll.cbegin(), coll.cend(), //source
ostream_iterator<int>(cout, " ")); //dest
cout << endl;
//remove all elems with value 3
remove(coll.begin(), coll.end(), //range
3); //value
//print all elems of the collection
cout << "post: ";
copy(coll.cbegin(), coll.cend(), //source
ostream_iterator<int>(cout, " ")); //dest
cout << endl;output:
pre: 6 5 4 3 2 1 1 2 3 4 5 6
post: 6 5 4 2 1 1 2 4 5 6 5 6remove() did not change the #elems in the collection for which it was called, but t changed their order as if the elements has been removed. Each elem with value 3 was overwritten by the following elems. At the end of the collection, the old elems that were not overwritten by the alg remain unchanged. Logically, these elems no longer belong to the collection.
list<int> coll;
//insert elems from 6 to 1 and 1 to 6
for(int i=1; i<=6; ++i) {
coll.push_front(i);
coll.push_back(i);
}
//print all elems of the collection
cout << "pre: ";
copy(coll.cbegin(), coll.cend(), //source
ostream_iterator<int>(cout, " ")); //dest
cout << endl;
//remove all elems with value 3
//- retain new end
list<int>::iterator end = remove(coll.begin(), coll.end(),
3); //value
//print resulting elems of the collection
copy(coll.begin(), end, //source
ostream_iterator<int>(cout, " ")); //dest
cout << endl;
//print #removed elems
cout << "#removed elems: "
<< distance(end, coll.end()) << endl;
//remove "removed" elems
coll.erase(end, coll.end());
//print all elems of the modified collection
copy(coll.cbegin(), coll.cend(), //source
ostream_iterator<int>(cout, " ")); //dest
cout << endl;output:
6 5 4 3 2 1 1 2 3 4 5 6
6 5 4 2 1 1 2 4 5 6
#removed elems: 2
6 5 4 2 1 1 2 4 5 6manipulation algs - those that remove elems and those that reorder or modify elems - have another problem on associative or unordered containers, which cannot be used as a dest.
To remove elems in associative containers? Call their member functions, e.g. erase()!
A container might have member funcs that provide much better performance. Again, take remove() as an example: if you call remove for elems of a list, the alg doesn't know that it is operating on a list and thus does what it does for any container - reorder the elems by changing their values. If, e.g., the alg removes the 1st elem, all the following elems are assigned to their previous elems, which contradicts the main advantage of lists - the ability to insert, move and remove elems by modifying the links instead of the values.
To avoid bad performance, lists provide special member funs for all manipulating algs, which should be called instead.
//remove all elems with value 3 (poor peformance)
coll.erase(remove(coll.begin(), coll.end(), 3),
coll.end());
//remove all elems with value 4 (good performance)
coll.remove(4);