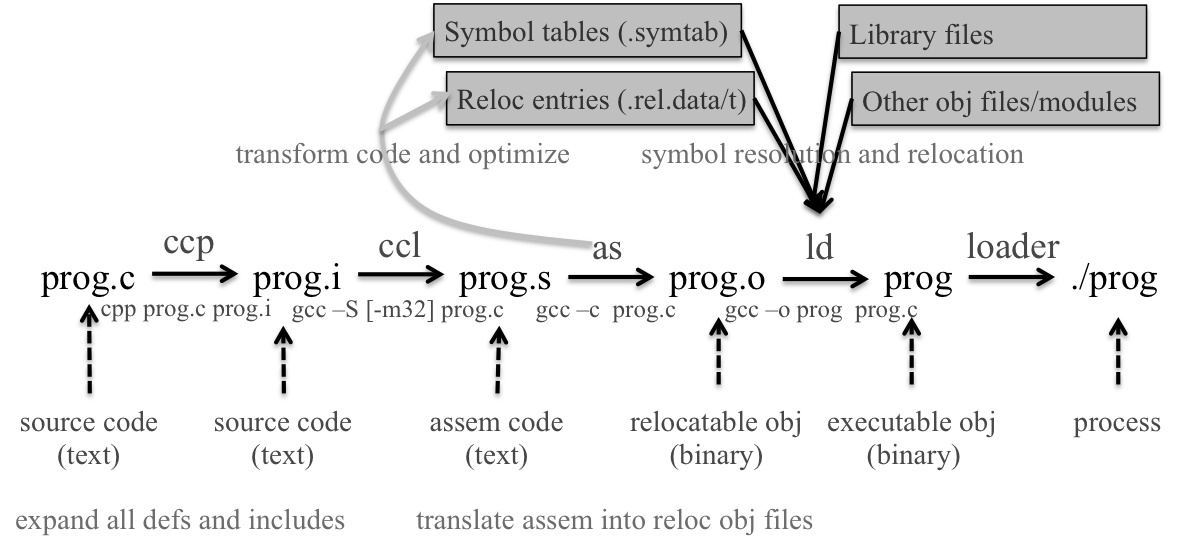
Linking is the process of collecting and combining various pieces of code and data into a single file that can be loaded (copied) into memory and executed. Linking is performed automatically by programs called linkers, which enable separate compilation.
Most compilation systems provide a compiler driver that invokes the language preprocessor, compiler, assembler, and linker.
invoke GCC driver to build the program: $gcc -O2 -g -o p main.c swap.c
Steps to translate source file into executable:
step1: the driver runs C preprocessor (cpp), translating C file main.c into an ASCII intermediate file main.i, which is still C code (gcc -E);
$cpp [other arguments] main.c /tmp/main.i
$cpp main.c main.istep2: the driver runs C compiler (ccl), which translates main.i into an ASCII assembly langu file main.s, where various optimizations are performed for the specific arch (gcc -S);
$ccl /tmp/main.i main.c -O2 [other arguments] -o /tmp/main.s
$gcc -S main.cstep3: the driver runs the assembler (as), which translates main.s into a relocatable obj file main.o;
$as [other arguments] -o /tmp/main.o /tmp/main.s
$gcc -c main.c
$nm main.ostep4: the driver goes through the same process to get swap.o;
step 5: finally, it runs the linker program ld, which combines main.o and swap.o, along with the necessary system obj files, to create the executable obj file p.
$ld -o p [sys obj files and args] /tmp/main.o /tmp/swap.ostep 6: to run the executable p, type its name in shell, which invokes a func in the OS called the loader, which creates a process by reading the file and creating an addr space for the process. Page table entries for the instrs, data and program stack are created and the register set is inited. Then the loader executes a jump instr to the first instr in the program.
cpp expands all macro definitions and include statements (and anything else starting with a #) and passes the result to the actual compiler.
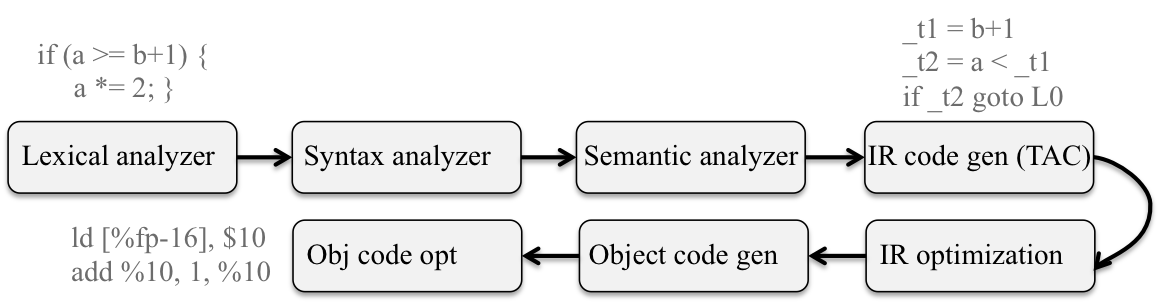
Lexical analyasis (scanner): reads stream of chars making up the source code and groups into tokens, including keywords, identifiers, integers, operators and special symbols, etc.
int a;
a = a + 2;
//return: int(keyword), a(id), ;(special symbol) ...Syntax analysis (parser): the tokens during scanning are grouped together using a context-free grammer. Ouput is a parse tree or a derivation.
//to parse a+2
Expr -> Expr + Expr
-> Variable + Expr
-> T_IDENTIFIER + Expr
-> T_IDENTIFIER + Constant
-> T_IDENTIFIER + T_INTCONSTANTSemantic analysis: the parse tree or derivation is next checked for semantic errors.
//scanned valid tokens and successfully match rules
int arr[2], c;
c = arr * 10;
//type-check error: incompatible typeIntermediate code generation: creates intermediate representation for the source code; the representation is easy to generate and easy to translate into the final assembly code. Commonly used is three-address code (TAC), which is a generic assembly language.
//source code | //TAC codes
a = b * c + b * d | _t1 = b * c
| _t2 = b * d
| _t3 = _t1 + _t2
| a = _t3Intermediate code optimization: optimizes the TAC codes to produce the smallest, fastest and most efficient form, still in TAC codes.
//before opt | //after opt
_t1 = b * c | _t1 = b * c
_t3 = _t1 + 0 | a = _t2
_t3 = b * c
_t4 = _t2 + _t3
a = _t4Object code generation: translate TAC codes into assembly ones. Memory locations are selected for each variable, and instructions are chosen for each operation.
Object code optimization: transforms the obj code into tighter, more efficient obj code, to make efficient use of precessor(s) and registers.
symbol table
a symbol table contains info about all the ids in the program along with important attributes like type and scope. Ids can be found in the lexical analysis phase and added to the symbol table. During the two phases that follow (syntax and semantic analysis), the compiler updates the id entry in the table to include info about its type and scope. When generating intermediate code, the type of the var is used to determine which instrs to aid in register allocation. The mem loc determined in the code gen phase might also be kept in the symbol table.
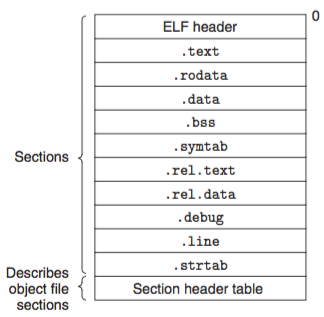
Assembler takes as input the assembly code generated by the compilation step, and translates it into machine code as an obj file. An obj file is a binary representation of the source program.
//assembly | //machine code
push %ebp | 0: 55
mov %esp, %ebp | 1: 89 ec
xor %eax, %eax | 3: 31 c0The assembler gives a memory location to each variable and instruction, and the location is actually represented symbolically or via offsets. It also make a list of all the unresolved references that presumably defined in other obj file or libraries, e.g. printf. A typical obj file contains the program text (instructions) and data (constants and strings), info about instrs and data that depend on absolute addr, a symbol table of unresolved references, and psbly some debugging info. (nm main.o)
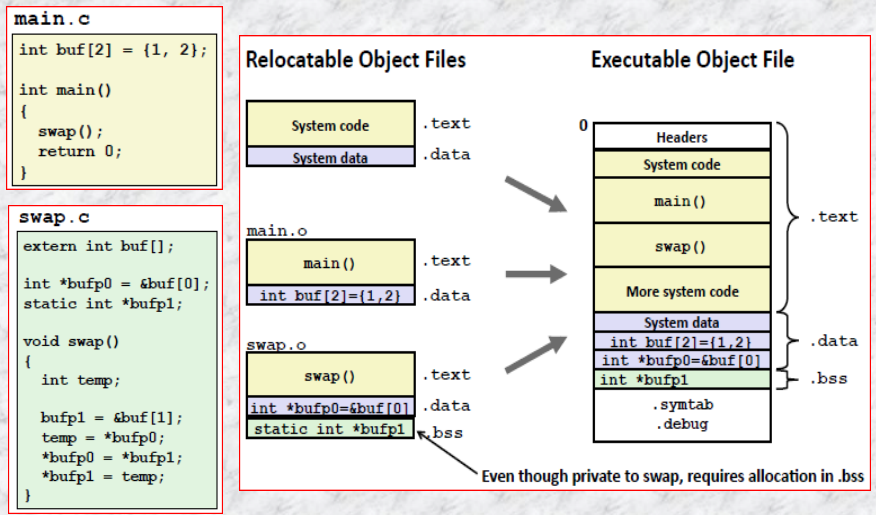
Static linkers such as the Unix ld program takes as input a collection of relocatable obj files and command-line arguments and generate as output a fully linked executable obj file that can be loaded and run. The input relocatable obj files consist of various code and data sections. Instructions / initialized global variables / uninit variables are in different sections.
To build the executable, the linker must perform two main tasks:
Object files come in three forms:
Compilers and assemblers generate relocatable obj files (including shared obj files). Linkers generate executable obj files. Technically, an obj module is a sequence of bytes, and an obj file is an obj module stored on disk in a file.
relocatable obj files
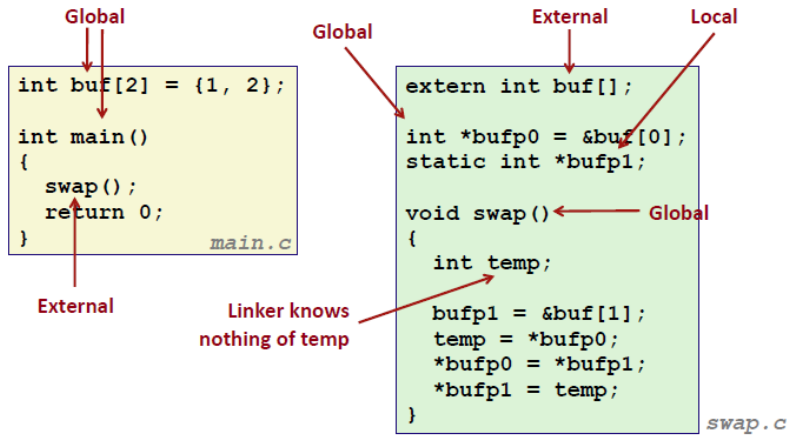
Each relocatable obj module, m, has a symbol table that contains info about the symbols that are defined and referenced by m. In the context of a linker, there are three different kinds of symbols:
Symbol tables are built by assemblers, using symbols exported by the compiler into the assembly-language .s file. An ELF symbol table is contained in the .symtab section. It contains an array of entries.
typedef struct {
int name; //byte offset into str table that points to symbol name
int value; //symbol's addr: section offset, or VM addr
int size; //obj size in bytes
char type:4, //data, func, sec, or src file name (4 bits)
binding:4; //local or global (4 bits)
char reserved; //unused
char section; //section header index, ABS, UNDEF or COMMON
} Elf_symbol;Each symbol is associated with some section of the obj file, denoted by the section field, which is an index into the section header table. There are three special pseudo sections that don't have entries in the section header table:
value gives the alignment requirement, and size gives the min size.//COMMAND: objdump -r -d -t main.o
//Alt CMD: readelf -s main.o
main.o: file format elf32-i386
//l=local, g=global;
//d=debug, f=file, O=object, F=function
SYMBOL TABLE:
00000000 l df *ABS* 00000000 main.c
00000000 l d .text 00000000 .text
00000000 l d .data 00000000 .data
00000000 l d .bss 00000000 .bss
00000000 l d .note.GNU-stack 00000000 .note.GNU-stack
00000000 l d .comment 00000000 .comment
00000000 g O .data 00000008 buf
00000000 g F .text 00000014 main
00000000 *UND* 00000000 swapThe first nine entries in the symbol table are local symbols that the linker uses internally, and we care more about the remaining ones:
buf is an 8B object located at an offset (i.e., value) of zero in the .data section. main is a 20B func located at an offset of zero in the .text section. swap is an external variable (UND).
symbol table entries for swap.o:
swap.o: file format elf32-i386
SYMBOL TABLE:
00000000 l df *ABS* 00000000 swap.c
00000000 l d .text 00000000 .text
00000000 l d .data 00000000 .data
00000000 l d .bss 00000000 .bss
00000000 l d .note.GNU-stack 00000000 .note.GNU-stack
00000000 l d .comment 00000000 .comment
00000000 g O .data 00000004 bufp0
00000000 *UND* 00000000 buf
00000004 O *COM* 00000004 bufp1
00000000 g F .text 00000035 swapbufp0 is a 4B inited obj starting at offset 0 in .data; next is a reference to the external buf symbol in the initialization code for bufp0; and, bufp1 is a 4B uninited data obj (with a 4B alignment requirement) that will eventually be allocated as a .bss obj when this module is linked; swap is a 53B func at an offset of zero in .text.
The linker resolves symbol references by associating each ref with exactly one symbol definition from the symbol tables of its input relocatable obj files. Symbol resolution is easy for references to local variables that are defined in the same module as the ref.
Resolving ref to global symbols is trickier. When the compiler encounters a symbol (either a var or func name) that is not defined in the current module, it assumes that it is defined in some other module, generally a linker symbol table entry, and leaves it for the linker to handle. If the linker is unable to find a def for the referenced symbol in any of its input modules, it prints an error msg and terminates.
Related funcs can be compiled into separate obj modules and then packaged in a single static library file. Application programs can then use any of the funcs defined in the library by specifying a single file name on the command line:
$gcc main.c /usr/lib/libm.a /usr/lib/libc.aAt link time, the linker will only copy obj modules that are referenced by the program, which reduces the size of the executable on disk and in memory.
On Unix systems, static libraries are stored on disk as archive, which is a collection of concatentated relocatable obj files, with a header that describes the size and loc of each member obj file.
-static tells the compiler driver that the linker should build a fully linked executable obj file that can be loaded into memory and run without any further linking at load time.
During the symbol resolution phase, the linker scans the relocatable obj files and archives left to right in the same sequential order that they appear on the compiler driver's command line. (The driver automatically translates any .c files on the cmd line into .o files.) During this scan, the linker maintains a set E of relocatable obj files that will be merged to form the executable, a set U of unresolved symbols (i.e., symbols referred to, but not yet defined), and a set D of symbols that have been defined in previous input files. Initially, E/U/D are empty.
The ordering of libraries and obj files on the cmd line is significant, and the general rule is to place libraries at the end of cmd line. And, if libraries are not independent, they must be ordered so that for symbol s that is referenced externally by a member of an archive, at least one def of s follows a ref to s on the cmd line. E.g., suppose foo.c calls funcs in libx.a and libz.a that call funcs in liby.a. Then, libx.a and libz.a must precede liby.a on the cmd line:
$gcc foo.c libx.a libz.a liby.aLibraries can be repeated on the cmd line if necessary to satisfy the dependence requirements. E.g., suppose foo.c calls a func in libx.a that calls a func in liby.a that calls a func in libx.a. Then libx.a must be repeated on the cmd line:
$gcc foo.c libx.a liby.a libx.aOnce the linker has completed the symbol resolution step, it has associated each symbol ref in the code with exactly one symbol def (i.e., a symbol table entry in one of its input obj modules). At this point, the linker knows the exact sizes of the code and data sections in its input obj modules. It is now ready to begin the relocation step, where it merges the input modules and assigns run-time addr to each symbol. Relocation consists of two steps:
When an assembler generates an obj module, it does not know where the code and data will ultimately be stored in memory. Nor does it know the locs of any externally defined funcs or global vars that are referenced by the module. So, whenever the assembler encounters a ref to an obj whose ultimate loc is unknown, it generates a relocation entry that tells the linker how to modify the ref when it merges the obj file into an executable. Relocation entries for code are placed in .rel.text, and for inited data are in .rel.data.
typedef struct {
int offset; //offset to the ref to relocate
int symbol:24, //symbol the ref should point to
type:8; //relocation type, tell the linker how to modify the new ref
} Elf32_Rel;Whereas 11 different relocation types are defined by ELF, we mainly concern two basic ones:
foreach section s { //iterate over each section
foreach relocation entry r { //iterate over each reloc entry in each sec
refptr=s+r.offset; //ptr to ref to be relocated
//relocate a PC-relative ref
if(r.type == R_386_PC32) {
//ADDR(s): run-time addr for the sec
refaddr = ADDR(s)+r.offset; //ref's runtime addr
//ADDR(r.symbol): run-time addr of the symbol
*refptr = (unsigned) (ADDR(r.symbol)) + *refptr - refaddr);
}
//relocate an absolute ref
if(r.type == R_386_32)
*refptr = (unsigned) (ADDR(r.symbol) + *refptr);
}
}relocating PC-relative references
main routine in the .text sec of main.o calls the swap routine, which is defined in swap.o.
Disassembly of section .text:
00000000 <main>:
0: 55 push %ebp
1: 89 e5 mov %esp,%ebp
3: 83 e4 f0 and $0xfffffff0,%esp
6: e8 fc ff ff ff call 7 <main+0x7> //swap()
7: R_386_PC32 swap //reloc entry
b: b8 00 00 00 00 mov $0x0,%eax
10: 89 ec mov %ebp,%esp
12: 5d pop %ebp
13: c3 ret call instr begins at sec offset 0x6 and consists of the 1-byte opcode 0xe8, followed by the 32-bit ref 0xfffffffc (-4 decimal), which is stored in little-endian byte order.
The relocation entry r consists of three fields:
r.offset = 0x7
r.symbol = swap
r.type = R_386_PC32These fields tell the linker to modify the 32-bit PC-relative ref starting at offset 0x7 so that it will point to the swap routine at run time. Now suppose the linker has determined that
ADDR(s) = ADDR(.text) = 0x80483b4
ADDR(r.symbol) = ADDR(swap) = 0x80483c8The linker first computes the run-time addr of the ref:
refaddr = ADDR(s) + r.offset
= 0x80483b4 + 0x7
= 0x80483bbIt then updates the ref from its current value (-4) to 0x9 so that it will point to the swap routine at run time:
*refptr = (unsigned) (ADDR(r.symbol) + *refptr - refaddr)
= (unsigned) (0x80483c8 + (-4) - 0x80483bb)
= (unsigned) (0x9)In the resulting executable obj file, the call instr has the following relocated form:
80483ba: e8 09 00 00 00 call 80483c8 <swap> //swap;At run time, the call instr will be stored at addr 0x80483ba. When the CPU executes the call instr, the PC has a value of 0x80483bf, which is the addr of the instr immediately following call instr. To execute the instr, the CPU performs the following steps:
push PC onto stack
PC <- PC + 0x9 = 0x80483bf + 0x9 = 0x80483c8Thus, the next instr to execute is the first instr of the swap routine, which is just what we want.
relocating absolute references
the swap.o module inits the global ptr bufp0 to the addr of the first element of the global buf array:
Disassembly of section .text:
00000000 <swap>:
0: 55 push %ebp
1: 89 e5 mov %esp,%ebp
3: 83 ec 10 sub $0x10,%esp
6: c7 05 00 00 00 00 04 movl $0x4,0x0
d: 00 00 00
8: R_386_32 bufp1
c: R_386_32 buf
10: a1 00 00 00 00 mov 0x0,%eax
11: R_386_32 bufp0
15: 8b 00 mov (%eax),%eax
17: 89 45 fc mov %eax,-0x4(%ebp)
1a: a1 00 00 00 00 mov 0x0,%eax
1b: R_386_32 bufp0
1f: 8b 15 00 00 00 00 mov 0x0,%edx
21: R_386_32 bufp1
25: 8b 12 mov (%edx),%edx
27: 89 10 mov %edx,(%eax)
29: a1 00 00 00 00 mov 0x0,%eax
2a: R_386_32 bufp1
2e: 8b 55 fc mov -0x4(%ebp),%edx
31: 89 10 mov %edx,(%eax)
33: c9 leave
34: c3 retint *bufp0 = &buf[0];Since bufp0 is an initialized obj, it will be stored in the .data sec of swap.o relocatable obj module. Since it is inited to the addr of a global array, it'll need to be relocated.
00000000 <bufp0>:
0: 00 00 00 00 //int *bufp0 = &buf[0];
0: R-386_32 buf //Relocation entry.data sec contains a single 32-bit ref, the bufp0 ptr, which has a value of 0x0. The relocation entry tells the linker that this is a 32-bit absolute ref, beginning at offset 0, which must be relocated so that it points to the symbol buf. Now, suppose the linker had determined that
ADDR(r.symbol) = ADDR(buf) = 0x8049454
*refptr = (unsigned) (ADDR(r.symbol)) + *refptr)
= (unsigned) (0x8049454 + 0)
= (unsigned) (0x8049454)In the resulting exe obj file, the ref has the following relocated form:
0804945c <bufp0>:
804945c: 54 94 04 08 Relocated!The linker has decided that at run time the var bufp0 will be located at mem addr 0x804945c and will be inited to 0x8049454, which is the run-time addr of the buf array.
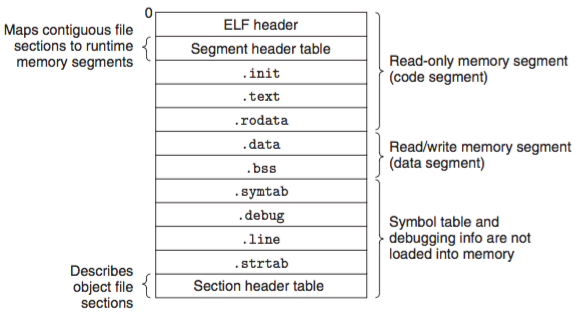
The format of an executable obj file is similar to that of a relocatable obj file. The ELF header describes the overall format of the file. It also includes the program's entry point, which is the addr of the first instr to execute when the program runs. The .text, .rodata and .data sections are similar to those in a relocatable obj file, except that these sections have been relocated to their eventual run-time mem addr. The .init section defines a small func, called _init, that will be called by the program's init code. Since the executable is fully linked (relocated), it needs no .rel sections.
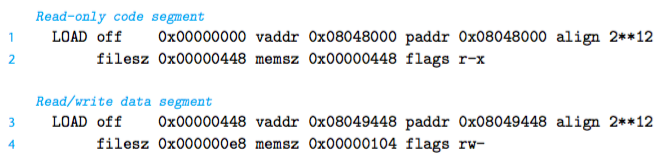
ELF executables are designed to be easy to load into mem, with contiguous chunks of the exe file mapped to contiguous mem segments. This mapping is described by the segment header table. From Fig. 7, we see that two mem segments will be inited with the contents of the exe obj file. Lines 1 and 2 shows that the code segment is aligned to a 4KB boundary, has r/x permissions, starts at mem addr 0x8048000, has a total mem size of 0x448 bytes, and is inited with the first 0x448 bytes of the exe obj file, which includes the ELF header, the segment header table, and the .init, .text and .rodata sections.
Lines 3 and 4 tell us that the data segment is aligned to a 4KB boundary, has r/w permissions, starts at mem addr 0x8049448, has a total mem size of 0x104 bytes, and is inited with the 0xe8 bytes starting at file offset 0x448, which in this case is the beginning of the .data section. The remaining bytes in the segment crspds to .bss data that will be inited to zero at run time.
Any Unix program can invoke the loader by calling the execve function, which copies the code and data in the executable object file from disk into memory, and then runs the program by jumping to its first instruction, or entry point. This process of copying the program into memory and then running it is known as loading.
Every Unix program has a run-time memory image similar to the one in Fig. 8. On a 32-bit Linux systems, the code segment starts at address 0x8048000. The data segment follows at the next 4KB aligned address. The run-time heap follows on the first 4KB aligned address past the read/write segment and grows up via calls to the malloc library. There is also a segment that is reserved for shared libraries. The user stack always starts at the largest legal user addr and grows down. The segment above the stack is reserved for the code and data in the memory-resident part of the OS kernel.
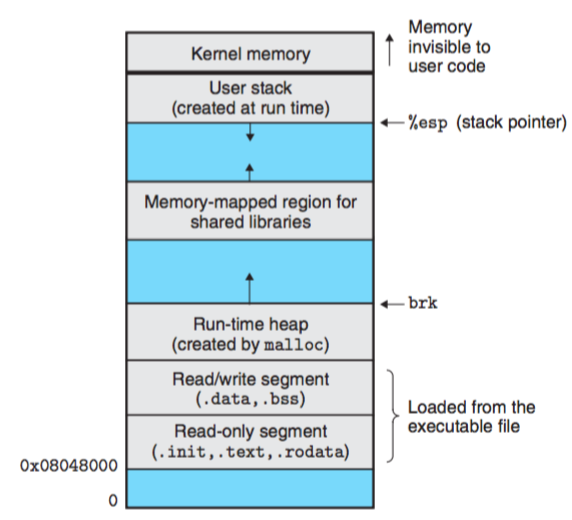
When the loader runs, it creates the memory image shown in Fig. 8. Guided by the segment header table in the executable, it copies chunks of the executable into the code and data segments. Next, the loader jumps to the program's entry point, which is always the address of the _start symbol. The startup code at the _start addr is defined in the obj file crt1.o and is the same for all C programs.
A shared library is an object module that, at run time, can be loaded at an arbitrary memory address and linked with a program in memory. The process is known as dynamic linking and is performed by a program called a dynamic linker. Shared libraries are also referred to as shared objects (.so).
Shared libraries are "shared" in two different ways:
#build a library
$gcc -shared -fPIC -o libvector.so addvec.c multvec.c
#link the library into the program
$gcc -o p2 main2.c ./libvector.so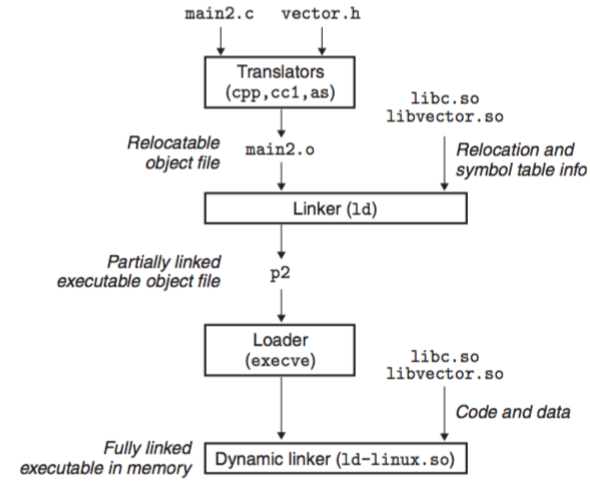
This creates an exe obj file p2 in a form that can be linked with libvector.so at run time. Do some of the linking statically when the exe file is created, and then complete the linking process dynamically when the program is loaded. Note that none of the code or data sections from libvector.so are actually copied into the exe p2 at this point. Instead, the linker copies some relocation and symbol table info that will allow reference to code and data in libvector.so to be resolved at run time.
When the loader loads and runs the exe p2, it loads the partially linked exe p2. Next, it notices that p2 contains a .interp section, which contains the path name of the dynamic linker, which is itself a shared object. The dynamic linker then finishes the linking task by performing the following relocations:
libc.so into some memory segment;libvector.so into another memory segment;p2 to symbols defined by libc.so and libvector.so.Finally, the dynamic linker passes control to the application. From this point on, the locations of the shared libraries are fixed and do not change during execution of the program.
Above sections discussed the scenario in which the dynamic linker loads and links shared libraries when an app is loaded, just before it executes. However, it is also psbl for an app to request the dynamic linker to load and link arbitrary shared libraries while the app is running, without having to link in the app against those libraries at compile time.
#include <stdio.h>
int main(){
printf("Hello world!\n");
return 0;
}The preprocessor replaces the line #include <stdio.h> with the text of the file 'stdio.h'. #include often compels with the use of #include guards or #pragma once to prevent double inclusion.
//pragma once
#pragma once
struct foo {
int member;
};
-------------
//include guards
#ifndef _HEADER_H
#define _HEADER_H
struct foo {
int member;
};
#endiftwo types of macros, object-like and function like.
//obj-like
#define <identifier> <replacement token list>
//e.g.:
#define PI 3.14159
//func-like
#define <identifier> (<para list>) <replacement token list>
//e.g.:
#define min(X, Y) ((X) < (Y) ? (X) : (Y))
//delete the macro
#undef <identifier>the if-else directives #if, #ifdef, #ifndef, #else, #elif and #endif can be used for conditional compilation:
#if VERBOSE >= 2
print("trace message");
#endif
----------
#ifdef __unix__
#include <unistd.h>
#elif defined _WIN32
#include <windows.h>
#endif-g option.-g option.At compile time, the compiler exports each global symbol to the assembler as either strong or weak, and the assembler encodes this info implicitly in the symbol table of the relocatable obj file. Funcs and inited global vars get strong symbols (buf, bufp0, main and swap). Uninited global vars get weak symbols (bufp1). Unix linker deals with multi defined symbols as follow:
Rule 1: multi strong symbols are not allowed;
/* foo.c */ | /* bar.c */
int x = 10; | int x = 11;
|
int main(){ | void f(){
reurn 0; | }
}Rule 2: given a strong symbol and multi weak symbols, choose the strong one;
/* foo2.c */ | /* bar2.c */
#include <stdio.h> | int x;
void f(); |
| void f(){
int x = 10; | x = 11;
| }
int main(){
f();
printf("x = %d\n", x);
return 0;
}At run time, func f changes the value of x from 10 to 11, which might be unexpected for main.
Rule 3: given multi weak symbols, choose any of the weak symbols.
/* foo3.c */ | /* bar3.c */
#include <stdio.h> | double x;
void f(); |
| void f(){
int x = 10; | x = -0.0;
int y = 42; | }
int main(){
f();
printf("x = 0x%x, y = 0x%x\n", x, y);
return 0;
}On an IA32 machine, doubles are 8B and ints are 4B. Thus, the asgnment x=-0.0 overwrites the memory locations for x and y with the double-precision floating-point representation of negative zero.
To avoid such subtle and nasty bug, invoke the linker with a flag -fno-common, which triggers an error if it encounters multi defined global symbols.