INPUT: A collection of jobs
![]() ,
where the ith
job is a 3-tuple
(ri, xi, di) of non-negative integers.
,
where the ith
job is a 3-tuple
(ri, xi, di) of non-negative integers.
OUTPUT: 1 if there is a preemptive feasible schedule for these jobs on one processor, and 0 otherwise. A schedule is feasible if every job job Ji is run for xi time units between its release time ri and its deadline di.
We consider greedy algorithms for solving this problem that schedule times in an online fashion, that is the algorithms are of the following form:
t = 0;
while there are jobs left not completely scheduled
pick a job Jm to schedule at time t;
increment t;
One can get different greedy algorithms depending on how
job Jm is selected. For each of the following method of selecting
Jm,
prove or disprove the that resulting greedy algorithms
produce feasible schedules, if they exist for the jobs
being considered.
As an example of EDF and SRPT consider the following instance: J1=(0, 100, 1000), J2=(10, 10, 100), J3=(10, 10, 101), and J3=(115, 10, 130).
EDF runs J1 from time 0 through time 10. From time 10 until time 20, EDF runs J2 because J2's deadline, 100, is less than J1's deadline, 1000, and less than J3's deadline, 101. From time 20 until time 30, EDF runs J3 because J3's deadline, 101, is less than J1's deadline, 1000, From time 30 to time 115, EDF runs J1. From time 115 to time 125, EDF runs J4 since J4's deadline, 130, is less than J1's deadline, 1000. EDF then runs J1 from time 125 to time 130. Thus for this input, EDF finishes all the jobs by their deadline.
SRPT runs J1 from time 0 through time 10. From time 10 until time 30, SRPT runs J2 and J3 (either can go first) because through out this time period, J2 and J3's remaining processing times are always equal and less than J1's remaining processing time, 90. From time 30 to time 115, SRPT runs J1. From time 115 to time 120, SRPT runs J1 since J1's remaining processing time throughout this period is smaller than J4's remaining processing time, 10. From time 120 to 130, SRPT runs J4. Thus for this input, SRPT finishes all the jobs by their deadline.
INPUT: Probabilities
![]()
OUTPUT: The minimum expected depth of a binary search tree
with n keys,
![]() ,
given that Ki is accessed
with probability pi.
,
given that Ki is accessed
with probability pi.
Recall that the expected depth of a key is given
by the formula
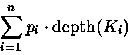
| j=1 | j=2 | j=3 | j=4 | |
| i=1 | .4 | 1 | 2 | |
| i=2 | UNDEFINED | .3 | .5 | 1.5 |
| i=3 | UNDEFINED | UNDEFINED | .1 | .4 |
| i=4 | UNDEFINED | UNDEFINED | UNDEFINED | .2 |
INPUT: A set positive integers
![]() ,
and a positive integer K.
,
and a positive integer K.
OUTPUT: 1 if there exists a subset S of X, and 0/1
variables
![]() such that
such that
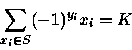
Here
![]() is the sum of all the xi.
So in words, you have three mutually exclusive choices for each number xi:
is the sum of all the xi.
So in words, you have three mutually exclusive choices for each number xi:
INPUT: Intervals
![]() over
the real line and a positive integer L such that
for all i,
over
the real line and a positive integer L such that
for all i, ![]() ,
it is the case that
0 < ai < bi < L. That is, all intervals start
after time 0 and end before time L.
Think as each interval (ai, bi) as being a request
for a room from time ai to time bi.
,
it is the case that
0 < ai < bi < L. That is, all intervals start
after time 0 and end before time L.
Think as each interval (ai, bi) as being a request
for a room from time ai to time bi.
OUTPUT: A non-intersecting sub-collection S of the intervals
that minimizes the maximum contiguous time that the room is empty
between time 0 and time L.
That is, assume that
As an example,
consider the input
![]() and L=50.
One feasible solution would be
and L=50.
One feasible solution would be
![]() .
For this S, the room would be empty during
the following time intervals
(0, 2), (5, 7), (10, 15), (20, 34), (44, 50). Thus
the longest time the room will be empty is the 14 time
units between time 20 and time 34.
There is no claim that this S is the optimal S for this input.
.
For this S, the room would be empty during
the following time intervals
(0, 2), (5, 7), (10, 15), (20, 34), (44, 50). Thus
the longest time the room will be empty is the 14 time
units between time 20 and time 34.
There is no claim that this S is the optimal S for this input.